Note: This blog post is a summary of the Swiftype’s Technical Journey with Elasticsearch Webinar. You can view it here.
Hosted search built on the Elastic Stack
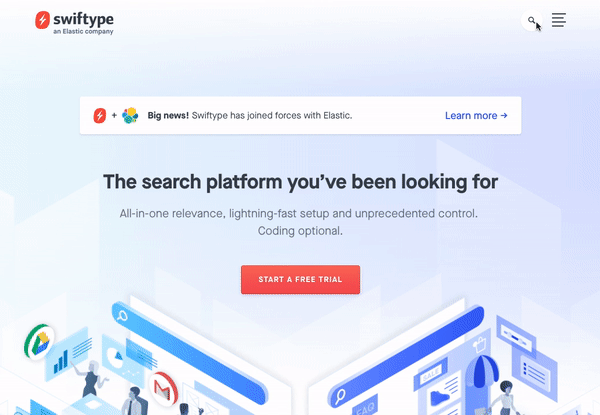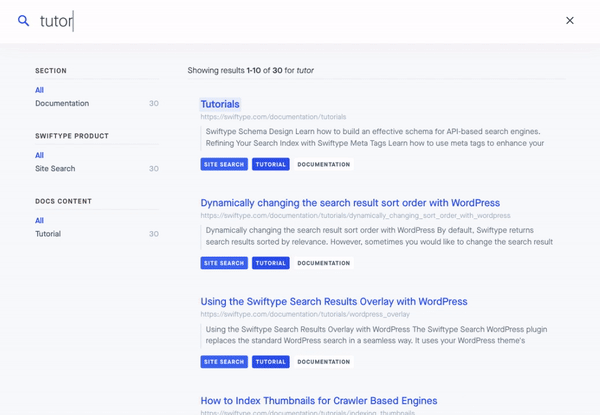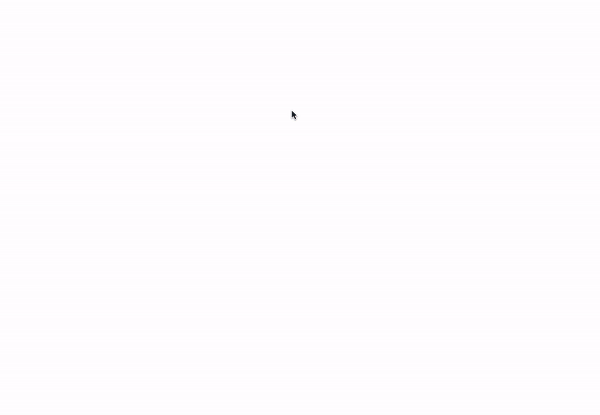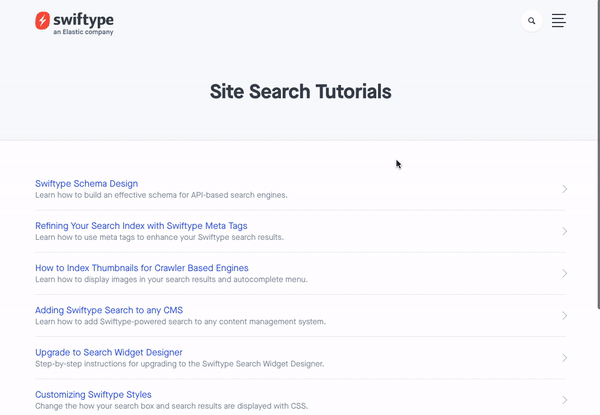
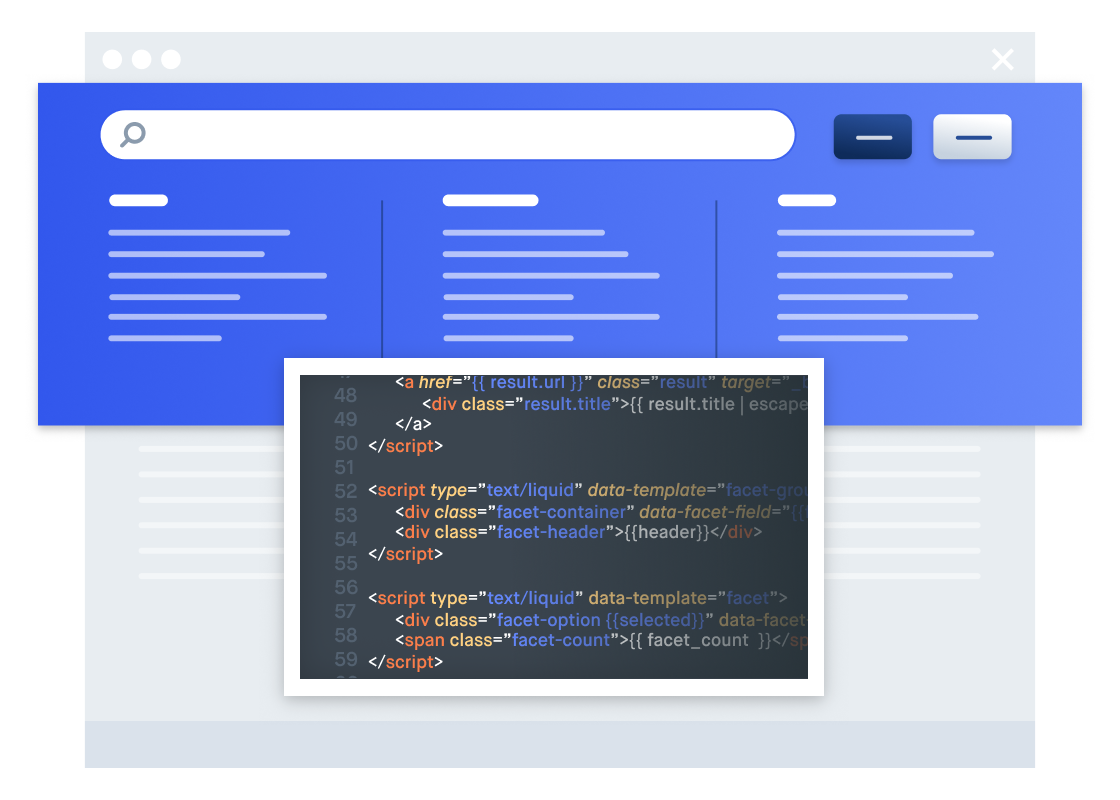
Swiftype is a search as a service solution built on the Elastic Stack. It abstracts away many of the difficulties of architecting a search engine and provides powerful out-of-the-box functionality. To make it easy to get search up and running, Swiftype provides a web crawler and API for ingesting data, an admin dashboard for managing your search experience, and multiple options for implementing your search UI including a JavaScript snippet as well as search and autocomplete jQuery libraries.
How Swiftype leverages the Elastic Stack
Building a hosted search solution that delivers relevant results for a large amount of varied data is difficult. Building a hosted search solution that allows for a wide-range of result customizations and relevancy tuning is even more of a challenge. Elasticsearch provided a strong backbone for us to build a robust and scalable search solution that works well for many use cases including ecommerce, customer support, marketing websites, digital publishing, mobile, and more.
Here’s how Swiftype leverages the Elastic Stack for scalability, quality of service, search functionality, and search analytics.
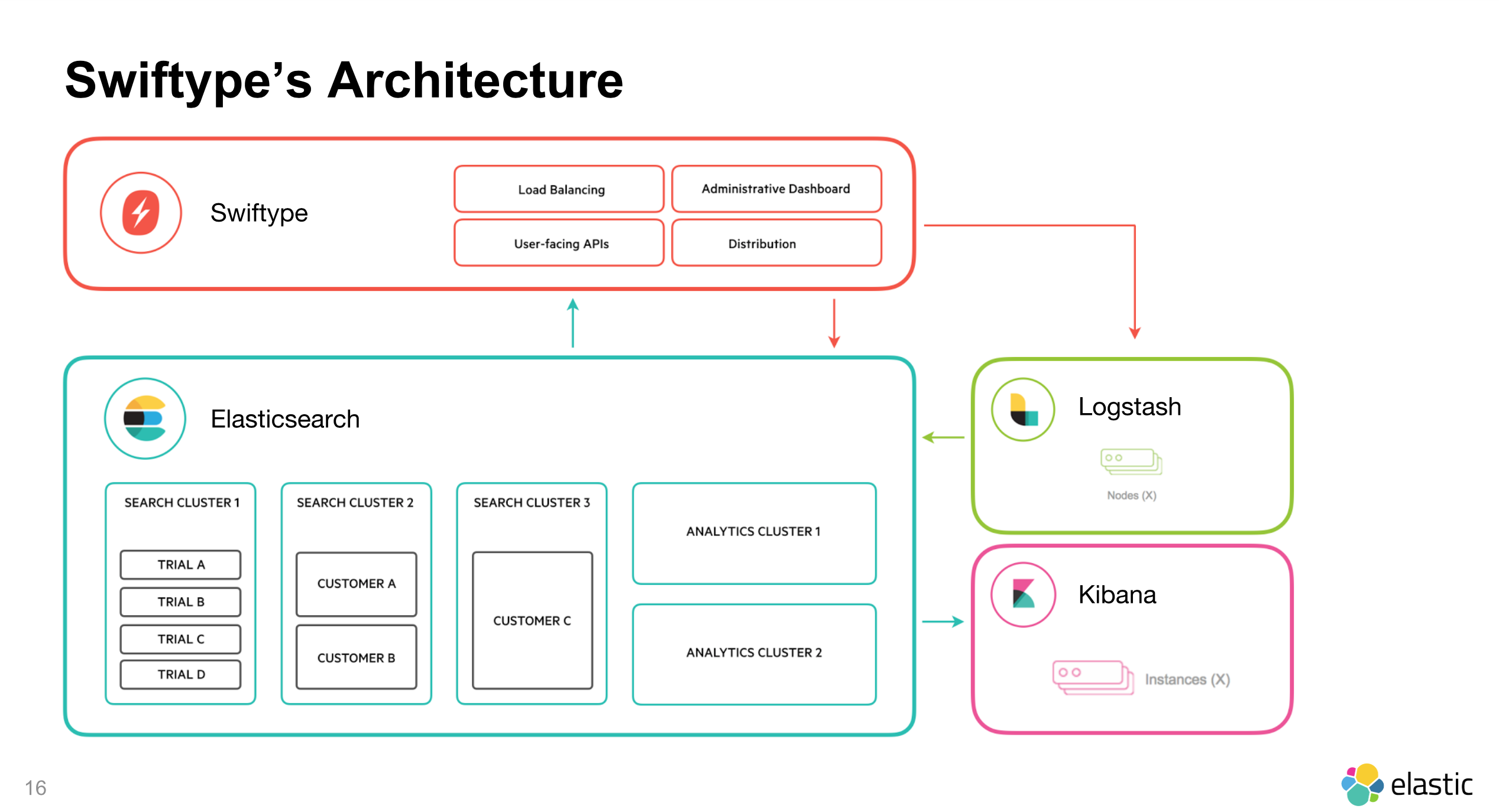
Scalability
To touch a little more on the scale of Swiftype, we currently support over 10,000 production search engines, have over 1 billion documents stored in Elasticsearch clusters, and serve over 5 billion queries a month. We have customers ranging from Fortune 500s to high-growth startups from large government organizations to small colleges that trust our search solution everyday.
No doubt, Elasticsearch has been absolutely critical to our ability to scale and its distributed design gave us a leg up in effectively managing large amounts of data. From a scalability and reliability standpoint, we can rest easy knowing that our underlying architecture is sound and will continue to support our growing business for years to come.

Quality of service
We’re constantly making improvements to our product and relevancy algorithm, and occasionally we will make some significant changes. When we do make large changes, Elasticsearch enables us to migrate our customers to updated search engines without taking them offline.
We have a few different ways of managing our Elasticsearch clusters depending on the needs of our customers, such as query load. In some cases, we have multiple customers on a single cluster, while in other cases we have a single customer on a single cluster. Furthermore, the distributed nature of Elasticsearch allows us to put our larger customers on multiple clusters to parallelize operations and provide high availability in the case of server failure.
Search functionality
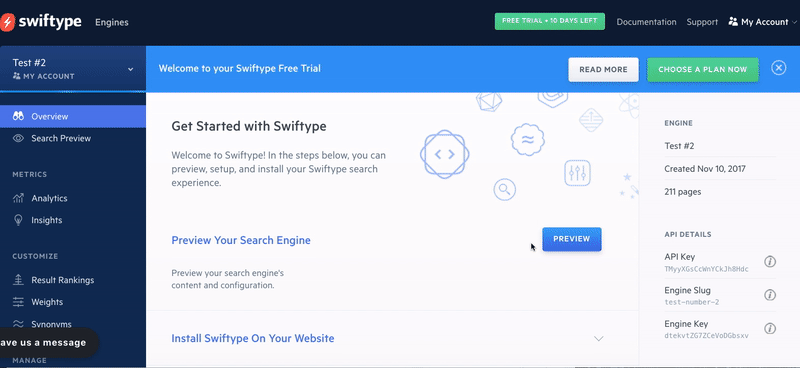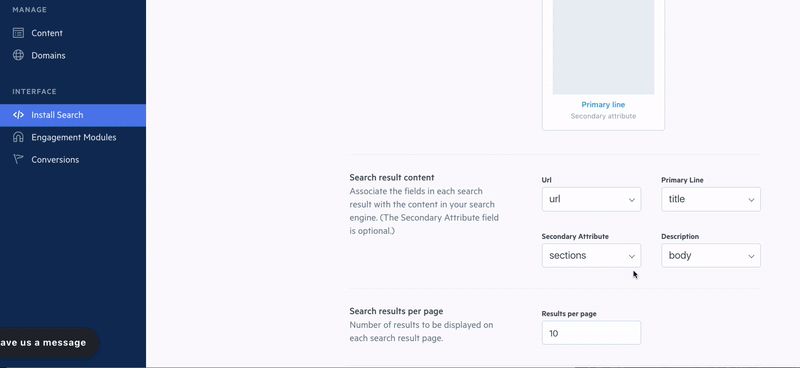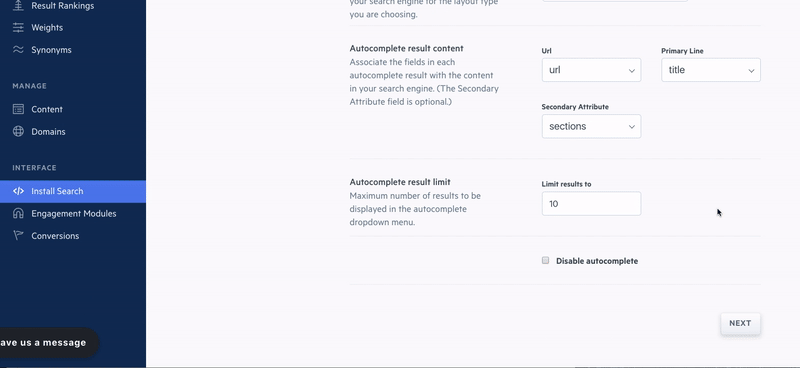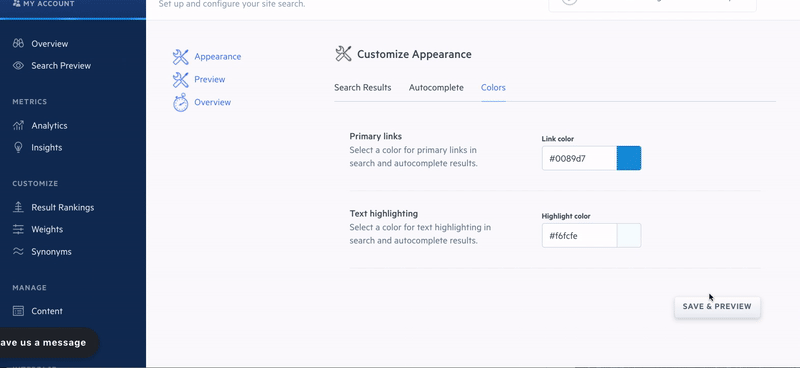
Diving more into search functionality, Elasticsearch enables us to provide autocomplete, spelling correction, and typo-tolerance to our customers right out-of-the-box. We abstract the coding of these features away from the user and give them full control over their search engine’s relevancy algorithm. When you create a Swiftype search engine, it automatically returns relevant results, but you can also customize your search results according to your needs.

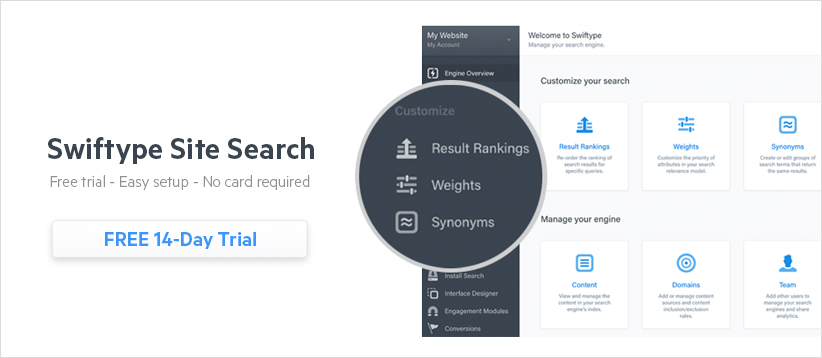
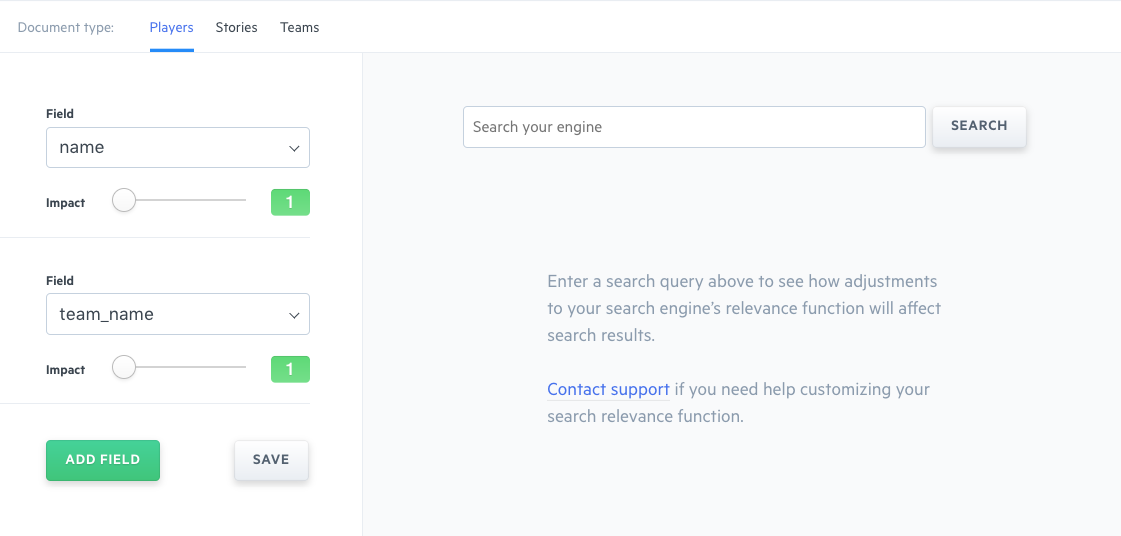
On a query-by-query basis, you can add to, remove from, and fully reorder search results through a drag-and-drop interface. You can also adjust the weights placed on your data fields and create synonyms which are groups of terms that are treated equally for the purposes of search (car = vehicle). Again, while no coding is required to fine-tune your search engine, we also expose these capabilities through the Swiftype API.
When you make changes to your Swiftype search engine, you can immediately preview your changes in the admin dashboard before pushing them live. For features like weighting, it’s a good idea to review how relevancy updates will affect search results before deploying them to production. Since our search solution is built on Elasticsearch, we can instantly update the relevancy algorithm powering your search engine — enabling you to see the effects of your changes in real-time and determine whether you want to keep them or restore your settings.
Search analytics
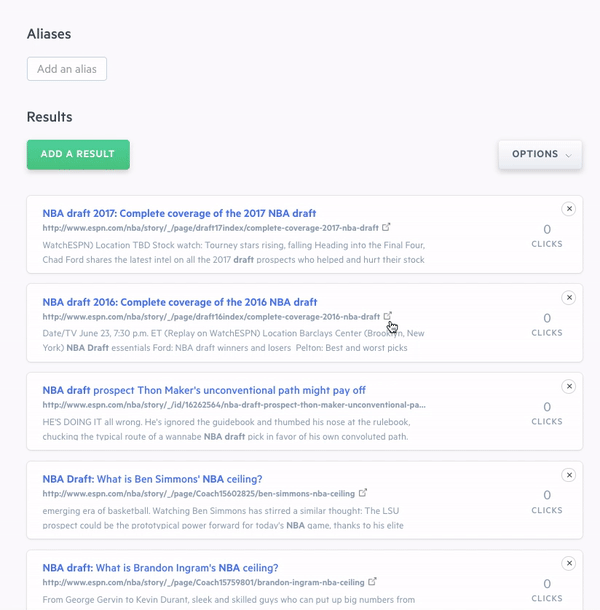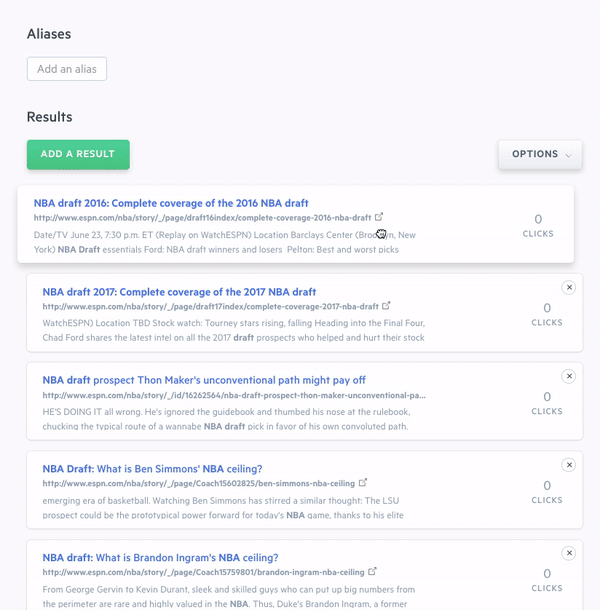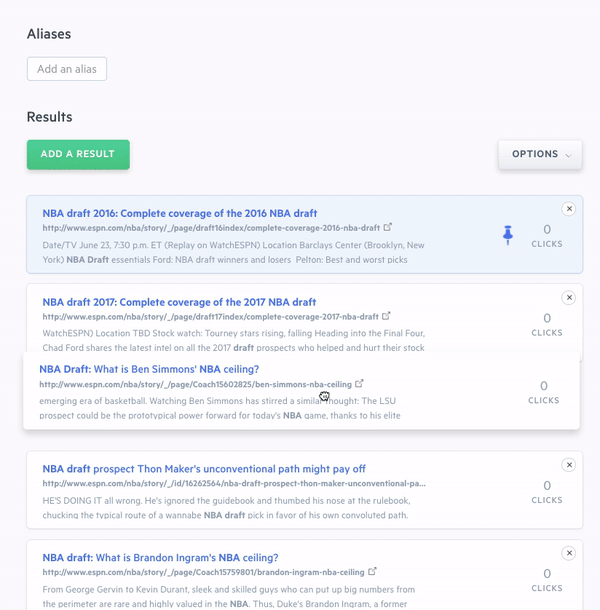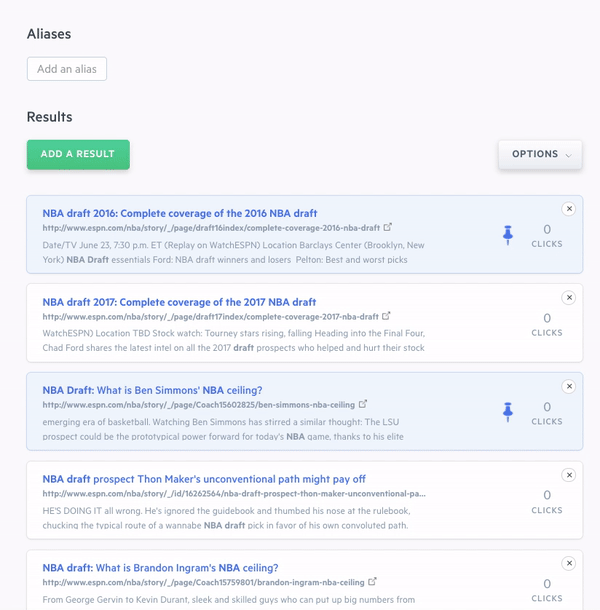
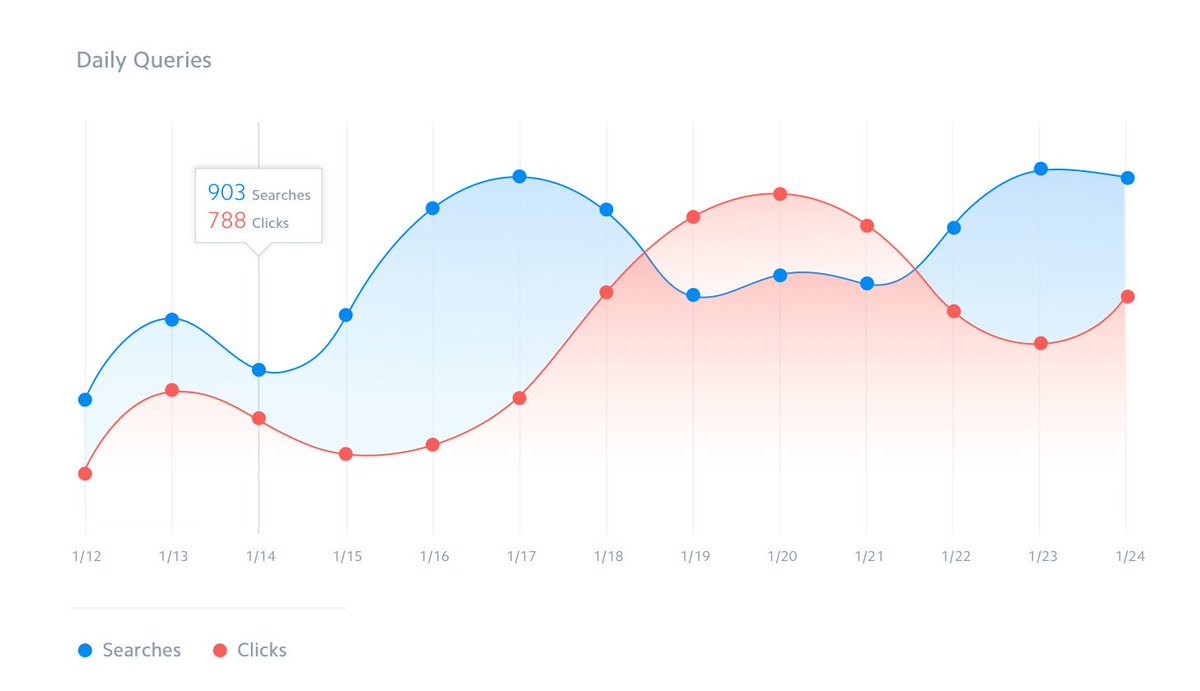
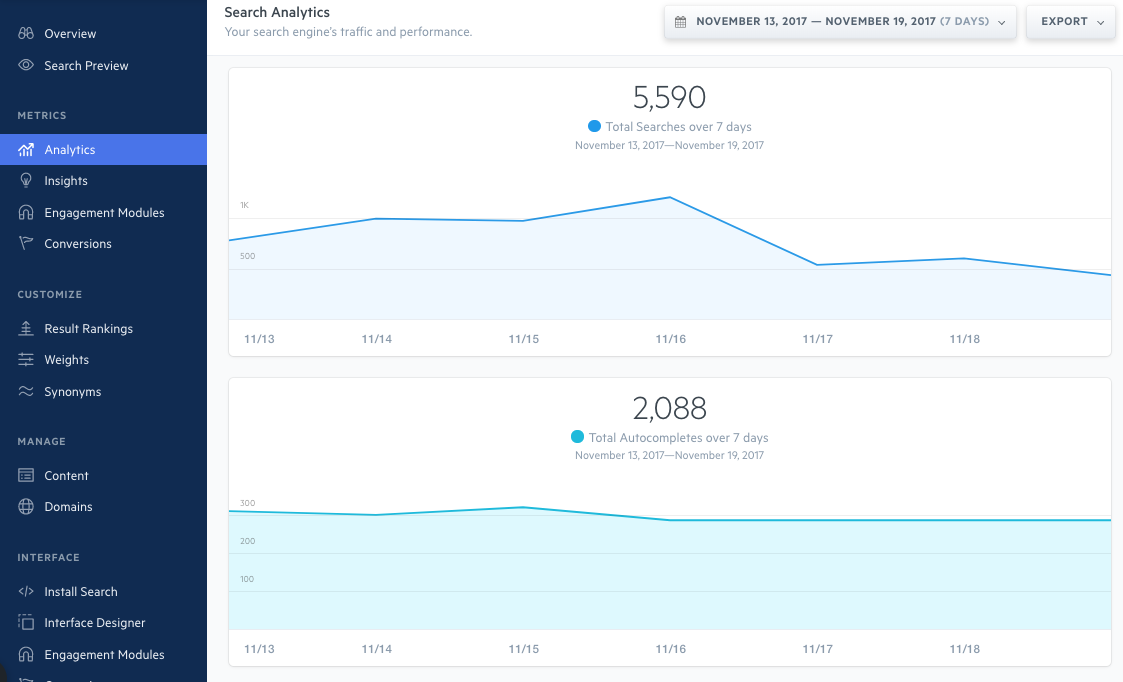
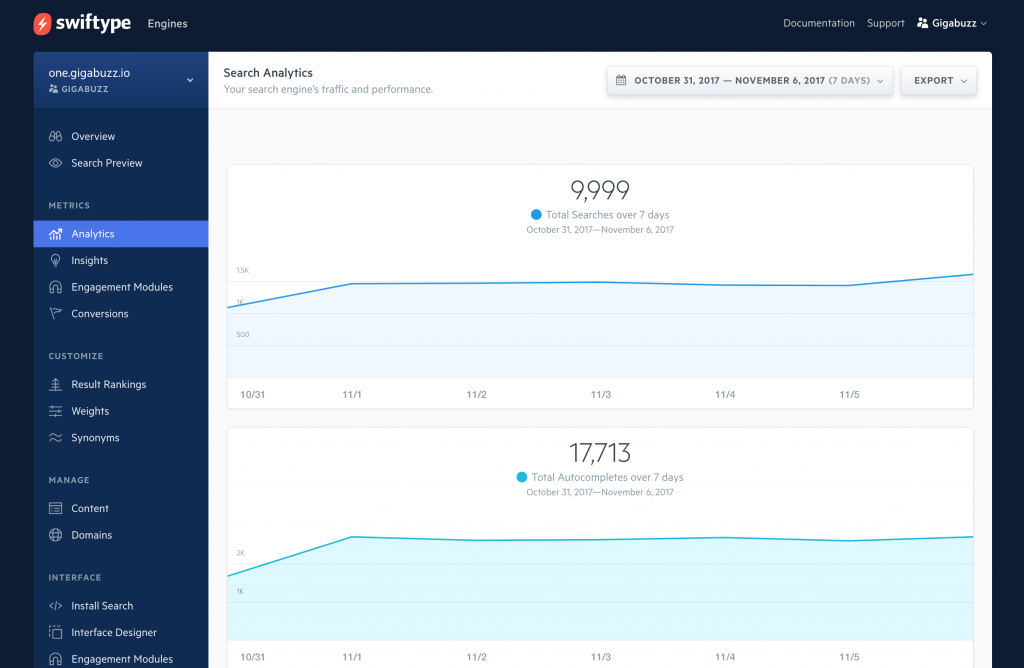
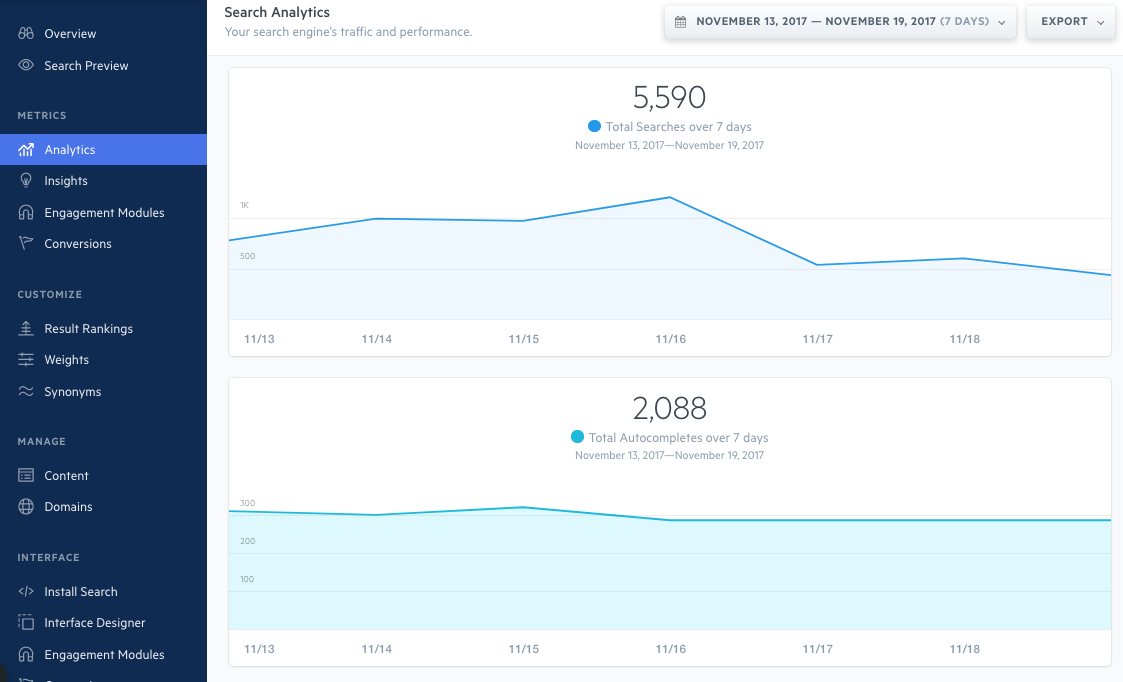
Aside from the robust search functionality we offer, the Elastic Stack has also enabled us to provide in-depth search analytics. In the Swiftype admin dashboard, we include metrics like volume of search queries, popular queries, queries returning no results, and CTRs on search results. This data has proved very valuable to our customers as they use it to better understand their website visitors, shape their content strategy, and optimize their relevancy algorithms.
The Elastic Stack: From a bet to best practice
We were an early adopter of Elasticsearch, first utilizing the technology when it was on version 0.19. Back in 2012, we made a bet on the Elasticsearch technology and community and that decision has turned out to be the right one. Over the past few years, the Elasticsearch open source community has grown tremendously and the project has gained tons of momentum. As of today, the Elastic Stack (Elasticsearch, Logstash, Beats, and Kibana) has been downloaded over 150 million times worldwide. Today, building search engines, logging systems, or business analytics dashboards with the Elastic Stack is far from a bet; it has become best practice.