The following is a Q&A with Mapbox’s Rafa Gutierrez about his experience working with Swiftype Site Search.
About Mapbox
If you’re not already familiar with Mapbox, they are a location data platform for mobile and web applications. They provide building blocks for developers to add location features like maps, search, and navigation into any experience they create. Mapbox’s strong customer portfolio includes The Weather Channel, Tableau, General Electric, and National Geographic. Together, Mapbox’s customers are shaping the way 300 million people explore the world.
Mapbox + Swiftype
Mapbox has been a Swiftype customer for a number of years now, and they use our search technology in a few different places on their website. Mapbox’s core use case for Swiftype is in their help center where they leverage our search technology to give their customers easy access to the documentation that’s relevant to their needs.
Recently, we spoke with Rafa Gutierrez, a Support Engineer at Mapbox, about his experience with Swiftype. During our conversation, Rafa touched on his use of Swiftype’s customizable web crawler, powerful search analytics and synonyms feature. Here’s our full conversation.
Question and Answer with Mapbox’s Rafa Gutierrez
Q: How does Swiftype compare to your previous search solution? What benefits have you experienced since implementing Swiftype?
A: Before we started using Swiftype, we had to build in specific page filtering for each API documentation page. This was cumbersome and we knew it wouldn’t scale for additional SDKs and other frameworks that we’d eventually have come online. We also needed a way for the search to cover the entirety of our site while still having some selective control over what it crawled. With Swiftype, we could just add a code snippet to all the areas of our site we needed covered by search.
We use Swiftype throughout the site but its main customization has been for our help and support pages. Swiftype crawls our pages selectively for content and pulls various categories and tags for filtering. We’re able to blacklist portions of our site to keep things relevant. We also have the ability to tailor content to the specific user and weigh out specific terms to differentiate content on similar searches.
Q: Tell us about the types of users that visit your website regularly. What are they looking for? How are you creating experiences that are tailored to their unique needs?
A: We’re a developer platform and our customers range from government organizations to autonomous vehicle manufacturers to on-demand transportation companies. Whether it’s finding a coffee spot on Foursquare or building navigation systems for autonomous cars – Mapbox does the geo stuff so developers can focus on building their product.
As we look to meet the needs of our wide array of users, we want ensure a streamlined and tailored experience that gives users fast access to relevant documentation so they can make the most of their use of Mapbox technology. Swiftype helps us deliver relevant content so our customers can find what they’re looking for faster.
Swiftype helps us deliver relevant content so our customers can find what they’re looking for faster.
Rafa Gutierrez
Support Engineer

Q: In what ways have you utilized the data from the Swiftype Search Analytics dashboard? What is your search data telling you about how users engage with your help center and product?
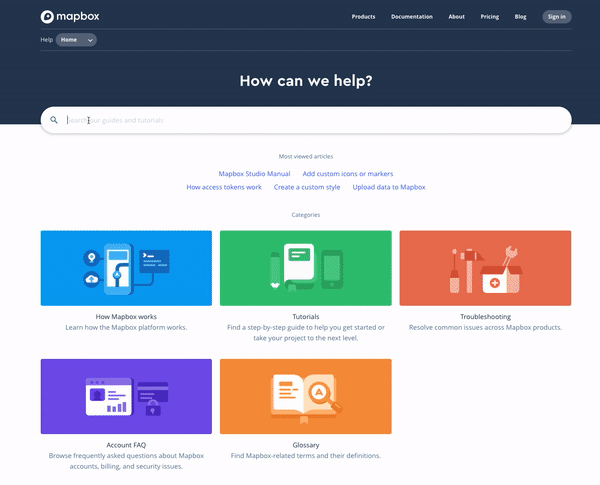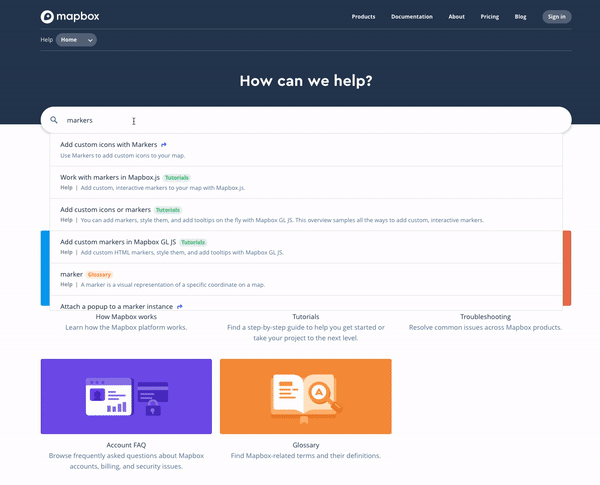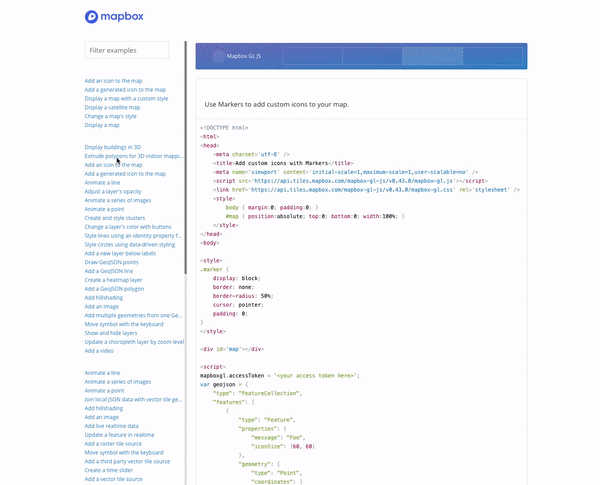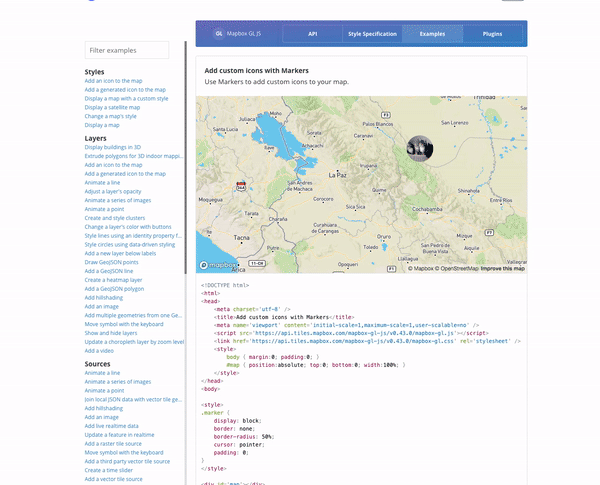
A: We dive into our metrics dashboard regularly to look for oddities or patterns that give us insight to how customers are finding the info they need. When customers search for terms that we’re not listing in our glossary or used for keywords in our categories, we can find these and add them to synonyms. For instance, we found a number of customers that would search for the phrase “add marker to map”. There are a few ways to do this with our tools so we restructured our docs to surface ones relevant to getting started with creating markers on a map. We also added synonyms to Swiftype to capture words that often get conflated with markers on a map like “pins” or “points”.
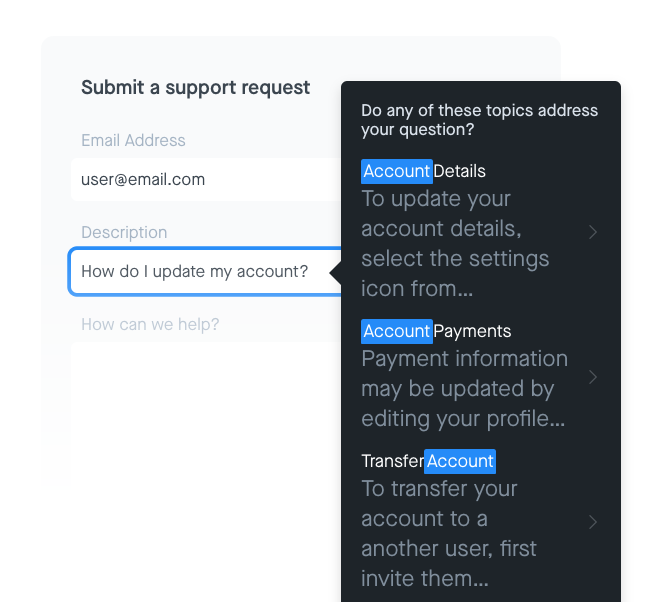
Q: How are you using the combination of search and quick glance features to drive down customer service requests?
A: We use Jekyll for a static HTML site generator so we can load up all relevant keywords, categories, and excerpts as metadata for our all of our help docs. By doing this, our search can pull this info into the quick glance as customers type in their search terms. At glance, they can see which category their term falls into and read brief excerpts before they click through. This was really valuable for us in that we could apply design treatments to results and watch search results get clicked through more than 50% of the time, reduced our searches with no clickthroughs by 16%, and nearly eliminated results with multiple clicks.
We also used the search in our contact form to provide an extra layer of assistance to ensure our customers didn’t overlook a doc before contacting us. We’re continuing to iterate on this approach for our next release.