Why use the Swiftype API?
The Swiftype API gives you full control over your search engine
The Swiftype API gives you full control over the schema of your search engine and the content that you index. With the Swiftype API endpoints, you are able to index data, execute search queries, and access rich analytics.
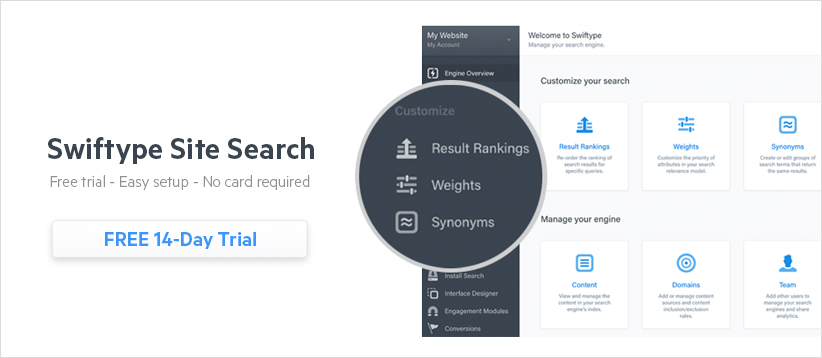
When you use the Swiftype API to index content for your search engine, you can still use the Swiftype Dashboard to fine-tune the relevancy of your search engine. With the Swiftype Dashboard, you can re-rank search results on a query-by-query basis, adjust the weights placed on each of your data fields, and set synonyms.
Swiftype REST API and Client Libraries
Swiftype’s API is a JSON-based REST API, making it easy to use with a JSON parser and HTTP client. Swiftype also supports a read-only public API with JSON, so you can execute cross-domain search requests instead of tunneling through your server. Furthermore, if you’d prefer to interact with your Swiftype search engine via a client library, we currently support libraries for:
Getting started with the Swiftype API
Here’s a quick overview of how to get started with the Swiftype API. For more detailed information, check out our API Quick Start Documentation.
Create a schema that fits your data model
Your schema will determine what content Swiftype will index and how it will be configured for search. When designing your schema, you’ll need to create a Document Type for each set of Documents that you wish to make searchable.

From a high level, you’ll design your schema for each set of Documents by determining which data fields to index and what types they should be. Then, you’ll create a Document Type to hold the set of Documents that will conform to the schema you’ve designed.
For more information, check out our Schema Design Tutorial.
Perform an initial content index
When you’re ready to start indexing your content, you can use a few different bulk operations to get your data flowing to Swiftype.
Indexing a very large number of documents? Consider using the Swiftype asynchronous indexing API.
Update Swiftype documents when your database is updated
When an item in your database changes, you’ll need to update it in Swiftype so that your search engine stays up-to-date.
In general, the approach to using the Swiftype API will follow this pattern: perform a create_or_update request when content is saved and a delete request when content is removed (or hidden).
Building your search UI
When you use the Swiftype API, the standard embed install code for implementing search on your website is not available because it doesn’t work with custom Document Types. Therefore, you’ll need to implement search using the Swiftype Search jQuery plugin which is written to be flexible based on your specific use-case. To get started with the plugin, you will need to have at least three elements on your page: a form, an input field within the form, and a container for results.
Key API Endpoints and Public API
Key API Endpoints:
- Search – The search endpoints enable you to search an entire engine or a single Document Type and customize the search query that you execute.
- Autocomplete – The Autocomplete endpoint supports nearly all of the same options as the search endpoint, but performs prefix matches on fields rather than token matching.
- Indexing – Once you’ve created your search engine and set up your schema, you can index your data using the Indexing endpoints. Note that you’ll have to keep your Swiftype engine up-to-date by hitting the Swiftype API whenever your database is updated.
- Analytics – The Analytics endpoints allow you to extract and record analytics information from a search engine. These endpoints provide the same analytics details that are available in the Swiftype dashboard.
Read-only Public API
In addition to the private API which is secured with your API key, Swiftype supports a read-only public API that uses your Search Engine’s Engine Key. The public API is read-only, so it is appropriate for using from client-side JavaScript or a mobile app where you do not want to expose your read-write API key.
Have questions or interested in learning more about Swiftype Site Search? Head over to the Swiftype Community Forum.